MySQL - 汇总篇
# 1. 数据库相关概念
数据库(Database):Database是按照数据结构来组织、存储和管理数据的仓库。
数据库管理系统(Database Management System):数据库管理系统是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。DBMS可分为关系型数据库管理系统(Relational Database Management System:RDBMS)与NoSQL(Not only SQL:对不同于传统的关系数据库的数据库管理系统的统称)。
数据库系统(Database System):数据库系统,是由数据库及其管理软件组成的系统。
现实中可能会经常听到一些人使用“数据库”(Database)来表示“数据库管理系统”(Database Managment System)这一概念,但其实这是两个不同的概念,只是被简化了,例如我们通常使用“法人”表示“法人代表”,但其实“法人”表示的是组织。
模式(schema):关于数据库和表的布局及特性的信息。
在某些时候,schema也可用于表示数据库。
表(table):数据库中的特定类型数据的结构化清单。
列(column):表中的一个字段。所有表都是由一个或多个列组成的。
行(row):表中的数据是按行存储的,所保存的每个记录存储在自己的行内。有时也称为记录(record)。
数据类型(datatype):每一列都可以根据自身的特性选择特定的数据类型。
主键(primary key):通常用于确定唯一的行,所以主键是不能重复的。
外键(foreign key):表中存储的与其他表主键关联的键,叫外键。
索引(index):相当于对列添加目录,用于加速列的查询。
SQL:结构化查询语言(Structured Query Language)的缩写。用于与数据库通信。
# 2. MySQL概念及安装
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。因为其开源的特性所以成为了当下较为流行的DBMS。目前为止MySQL已经更新到了8这个大版本,也算是久经沙场了。
对于初学者来说,你可以使用MySQL自带的命令行工具来学习MySQL,也可以使用第三方MySQL管理软件,例如开源的Dbeaver (opens new window)。
MySQL官方网站:https://www.mysql.com/ (opens new window)
直接下载MySQL社区服务端:MySQL Community Server Download (opens new window),根据自己需求下载压缩包或者是MSI安装程序,新手建议选择MSI安装程序。
下载完成之后双击安装程序即可,过程选项看着选,看不懂就翻译,这里不多赘述。
MySQL 8.0参考手册 (opens new window),下载安装等相关指南都在里面了,如果只是下载和入门只需要过一下Installing and Upgrading MySQL (opens new window)和Tutorial (opens new window)这两个篇章就行了(看着吃力就翻译)。
安装完成之后,尝试使用 mysql -u root -p ,根据提示输入密码即可连接到本地MySQL服务端。
提示没有mysql这个指令则需要将mysql安装目录下的bin目录添加到环境变量即可
登录之后可以 show databases; 查看所有数据库,use {database_name} 切换数据库,show tables;查看当前数据库下的所有表,describe {table_name};查看表结构等。(大括号里替代成具体的数据库/表的名称)
# 3. 基本关键字
以下均使用table代替表名,column代替列名。
# 3.1 select
用于查询数据。
常见用法:
- 查询全部数据:
select * from table; - 查询单/多列:
select column/column1,column2 from table;
在使用列名是可以使用表名.列名的写法,例如select table.column from table;,这在之后的联表查询会经常使用。
# 3.2 distinct
用于剔除结果中的重复数据。
常见用法:
- 查询去重:
select distinct column from table;
# 3.3 limit
限制结果集。不指定正反则默认为正序,即按照asc方式进行排序.
常见用法:
- 限制为1条记录:
select * from table limit 1; - 偏移限制-写法1:
select * from table limit 2 , 3; - 偏移限制-写法1:
select * from table limit 3 offset 2;
以上两种写法都代表从第二条记录后取3条数据,即(3,4,5)
# 3.4 order by
用于对数据排序。
常见用法:
- 正序排序1:
select * from table order by column; - 正序排序2:
select * from table order by column asc; - 倒序排序:
select * from table order by column desc; - 多列排序:
select * from table order by column1 asc,column2 desc;
# 3.5 where
用于对数据的过滤,其后可以接子句等其他表达式。
常见用法:
- 查询列值为1的记录:
select * from table where column = 1; - 查询列值为Null的记录:
select * from table where column is null;
在上述示例中我们只使用了“=”这个比较符号,在MySQL中还有这些比较符号可以在where语句中使用。
| 符号 | 含义 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
注意:null是这个列没有被赋值,而不是空字符串或者空格,也不是0。
# 3.6 not
常用于对逻辑取反。例如与between与in的取反。
# 3.7 between
常用于与where配合限制数据在某个区间内。
常见用法:
- 查询列值在1到10之间的记录:
select * from table where column between 1 and 10; - 查询列值不在1到10之间的记录:
select * from table where column not between 1 and 10;
# 3.8 in
常用于配合where语法,对数据进行结果集过滤。
常见用法:
- 查询列值在某个结果集的记录:
select * from table where column in (1,2); - 查询列值不在某个结果集的记录:
select * from table where column not in (1,2);
# 3.9 and
常用于与where语句配合,进行多条件的逻辑与判断
and与or同时使用and拥有更多的优先级,当同时使用时,推荐使用括号来明确优先级。
常见用法:
- 限制多属性查询:
select * from table where column1 = 1 and column2 = '计算机';
# 3.10 or
常用于与where语句配合,进行多条件的逻辑或判断
常见用法:
- 限制单属性多选择:
select * from table where column = 1 or column = 2; - 等上写法:
select * from table where column in (1,2); - 等上写法:
select * from table where column between 1 and 2;
and与or同时使用and拥有更多的优先级,当同时使用时,推荐使用括号来明确优先级。
# 3.11 like
用于模糊匹配,常与%一起使用。
另一个通配符是_,和%不同的是,_只能匹配单个字符。
常见用法:
- 左模糊:
select * from table where column like '1%'; - 右模糊:
select * from table where column like '%1'; - 中间模糊:
select * from table where column like '1%1'; - 左右模糊:
select * from table where column like '%1%';
模糊查询效率相对较低,如果可以简单查询的话,尽量使用简单明确的条件过滤。
# 3.12 regexp
用于进行正则表达式过滤。
常见用法:
- 查询包含1的结果集:
select * from table where column regexp '1'; - 查询包含
1%的结果集:`select * from table where column regexp '1.'
这里的.是正则表达式中用于匹配任意一个字符的,更多正则表达式的内容可以查看:Github:learn-regex (opens new window)
你可以不查询表来测试正则表达式,像这样select 'hello' regexp '[:alpha:]';,如果匹配则返回1,反之为0。
# 3.13 as
为列取别名。
常见用法:
- 别名:
select t.column as new_name from table as t; - 简写:
select t.column new_name from table t;
# 3.14 group by
将数据进行分组
常见用法:
- 按列分组:
select column count(column) from table group by column;
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
# 3.15 having
对分组数据进行过滤,类似where,但是where不能过滤分组数组,因为where是用于过滤行的,大多数情况下都可以使用having代替where。
常见用法:
- 分组并取count大于等于2的:
select column count(column) from table group by column having count(*) >= 2;
# 3.16 insert
新增记录。
常见用法:
- 按照表中的列顺序插入:
insert into table values(xxx,xxx,xxx...); - 自定义列及顺序插入:
insert into table(id,name,age...) values(null,'test',18...) - 多行插入:
insert into table values(xxx,xxx,xxx...),(xxx,xxx,xxx...)
你还可以在insert的values部分使用select语句返回的值作为value插入,需要注意的是涉及唯一的列需要变动时,如果id设置了自增那么可以不用插入id。
类似INSERT INTO table(column1,column2) SELECT column1, column2 FROM articles
# 3.17 update
更新记录。
常见用法:
- 更新指定数据:
update table set column1 = 1 where column2 = 2 - 更新多列:
update table set column1 = 1,column2 = 2 where column3 = 3
# 3.18 delete
删除数据。
常见用法:
- 删除指定记录:
delete from table where column1 = 1
# 4. 函数和运算符
此章节内容参考:官方手册 - 函数与运算符章节 (opens new window),w3school - MySQL函数 (opens new window)。
手册版本为8.0
# 4.1 运算符
四则运算(+、-、*、/)是最为常见的运算符。例如你想对一个数进行平方,可以这样 select column column * column square from table;
更多内容建议参考官方手册-运算符 (opens new window)
# 4.2 函数
如果是想细节了解函数,建议参考上面的官方手册。
以下仅简单按照几个方面介绍一些常用的函数。
- 字符串函数
- 数值函数
- 日期与时间函数
# 4.2.1 字符串函数
concat():用于拼接字符串,select concat('hello',' world !');
left():返回字符串左边n位,right()同理
length():返回字符串长度
lower():小写函数。大写为upper()
trim():删除前后空格,衍生函数:ltrim()、rtrim()
locate():返回子字符串在字符串中第一次出现的位置,SELECT LOCATE("3", "W3Schools.com");
repeat():重复字符串,SELECT REPEAT("SQL Tutorial", 3);
replace(): 替换字符串,SELECT REPLACE("SQL Tutorial", "SQL", "HTML");
reverse():反转字符串,SELECT REVERSE("SQL Tutorial");
substr():截取字符串,同substring(),SELECT SUBSTR("SQL Tutorial", 5, 3);
# 4.2.2 数值函数
abs():获取数值绝对值
avg():平均值,SELECT AVG(Price) AS AveragePrice FROM Products;
sum():求和
max():获取某列最大值,min()则相反
ceil():想上取整,同ceiling()
floor():向下取整
count():统计数值
mod():取模
greatest():返回列表最大值,SELECT GREATEST(3, 12, 34, 8, 25);,least()则相反
pow():幂运算,同power(),SELECT POW(4, 3);
rand():返回一个大于等于0小于1的浮点数。
round():将数值进行四舍五入。四舍五入到小数点后两位:SELECT ROUND(135.375, 2);
sqrt():平方根
除此之外还有许多都是数学函数,类似三角函数与反三角函数,弧度角度转换函数,对数函数等。
# 4.3.3 日期与时间函数
curdate():当前日期,同current_date()
curtime():当前时间,同current_time()
current_timestamp():当前日期加时间,类似now(),localtime()
datediff():日期差,SELECT DATEDIFF("2017-06-25", "2017-06-15");
adddate():增加日期,SELECT ADDDATE("2017-06-15", INTERVAL 10 DAY);
addtime():增加时间,SELECT ADDTIME("2017-06-15 09:34:21", "2");
此处基本没介绍年月日时分秒,但是相关函数都有。
# 4.4.4 流程控制函数
不知道为什么官方手册把这归结到函数而不是语句,但这都不是重点,重点是流程控制。
因为觉得介绍看的不如直接上代码,所以这里直接上代码。
- case、then、when、else、end
这是一套十分常见的流程控制组合。
mysql> SELECT CASE 1 WHEN 1 THEN 'one'
-> WHEN 2 THEN 'two' ELSE 'more' END;
-> 'one'
mysql> SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END;
-> 'true'
mysql> SELECT CASE BINARY 'B'
-> WHEN 'a' THEN 1 WHEN 'b' THEN 2 END;
-> NULL
2
3
4
5
6
7
8
- IF(expr1,expr2,expr3)
如果 expr1 为 TRUE(expr1 <> 0 和 expr1 <> NULL),IF() 返回 expr2。否则,它返回 expr3。
mysql> SELECT IF(1>2,2,3);
-> 3
mysql> SELECT IF(1<2,'yes','no');
-> 'yes'
mysql> SELECT IF(STRCMP('test','test1'),'no','yes');
-> 'no'
2
3
4
5
6
- IFNULL(expr1,expr2)
如果 expr1 不为 NULL,则 IFNULL() 返回 expr1;否则返回 expr2。
mysql> SELECT IFNULL(1,0);
-> 1
mysql> SELECT IFNULL(NULL,10);
-> 10
mysql> SELECT IFNULL(1/0,10);
-> 10
mysql> SELECT IFNULL(1/0,'yes');
-> 'yes'
2
3
4
5
6
7
8
- NULLIF(expr1,expr2)
如果 expr1 = expr2 为真,则返回 NULL,否则返回 expr1。这与 CASE WHEN expr1 = expr2 THEN NULL ELSE expr1 END 相同。
mysql> SELECT NULLIF(1,1);
-> NULL
mysql> SELECT NULLIF(1,2);
-> 1
2
3
4
# 5. 高级部分
# 5.1 子查询(subquery)
子查询就是嵌套在其他查询中的查询。
举个栗子
select column from table where column = (select column from table where column = 1)
以上是最为简单的子查询,接下来介绍一种作为计算字段的子查询
select column1 (select count(*) from table2 where table1.column1 = table2.column1) from table1
这里提前使用了联表,目的是为了查出当前的某些主题在其他表的其他统计信息。
# 5.2 连表查询(join)
连表查询是SQL中十分常见的做法,因为如果把所有信息都放在同一张表中的话,那么这张表将会十分复杂,并且有些信息可能是大量重复的数据,所以连表查询也可以减少数据库的空间占用。
通常的做法是提供多张表,然后在关联表中使用一个字段与主表的主键进行关联,因此关联表中的这个字段也被称为外键。
既然数据存放在不同表,那么使用简单查询就不可能查询出我们需要的所有信息,所以此时就需要使用连表查询。
举个例子,现在有一张商品表products与订单表orders,我们需要从订单金额大于500的商品信息(在商品表才有商品信息,订单表只有商品id),所以此时我们可以这样:
select product.product_name, orders.amount from orders, products where orders.product_id = products.id
在上面的SQL语句中,我们在查询了两个在不同表的字段 ( 使用表名.列名的方式,这种方式称之为 完全限定名) ,通过from后面添加两张表名(使用逗号隔开),并且在where条件中补充连接关系,这样便是一个最简单的连表查询。
如果不在where条件中补充联结关系,那么返回的结果将会是两表的笛卡尔积,这种方式也称之为交叉连接(cross join)。
- 内连接
连接其实也分为不同的类型,上述的写法其实是内连接的简化写法,事实上它和以下这种写法是一样的
select product.product_name, orders.amount from orders inner join products on orders.product_id = products.id
两者的区别在乎这里我们明确使用了inner join关键字进行内连接,同时使用on而不是where进行连接关系的补充。
连接不仅局限于两张表,如果需要连接多张表,则需要继续补充相应的连接关系。但是需要注意,连表是有性能代价的,连接的表越多,性能下降也越大。
- 外连接
外连接与内连接不同在于,内连接只会返回匹配的行,而外连接除了返回匹配的行还会返回不匹配的行。
外连接通常分为左外连接(left outer join,简写为left join)与右外连接(right outer join,简写为right join)。
MySQL是没有full join的,想实现这个功能可以考虑下面的组合查询(union)。
左外连接即使返回左表的所有行,即使行没有与右表相匹配,右连接则相反。
通过韦恩图可以获得更为直观的信息。
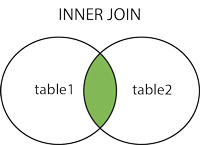


- 自连接
自连接是把同一张表进行联表查的方式,自连接的好处在于对于那些只在一张表使用子查询时,可以考虑自连接,因为自连接的性能通常会比子查询要好(需要你自己测试)。
下面举个例子,假设我们有张教师表,我们需要从该表中查询出所有科目等于id为1的老师的科目的教师姓名,此时如果使用子查询则可以:
select name, subject from teachers where subject = (select subject from teachers where id = 1);
自连接的方式:
select t1.name, t1.subject from teachers t1, teachers t2 where t1.subject = t2.subject and t2.id = 1;
# 5.3 组合查询(union)
组合查询其实就是把多个查询结果进行并集处理。在上述连表查询中我们提到过使用组合查询实现全连接,通过左连接与右连接进行并集处理,返回的结果正好是全连接,通过上述的韦恩图也可以非常直观的感受到。
组合查询的使用非常简单,但是这里仍然给出一个例子:
select name, age, level from teachers where age <= 30 union select name, age, level from teachers where level >= 3
上述的需求可能是,最近学校要选出一些教师,要求教师年纪最好要小(30之内),如果年纪大了的话,那么等级必须大于3,因此使用并集处理就可以获取我们所有符合条件的教师。
你可能会疑惑在这个情况下,使用or不也能完成嘛。事实上这里仅仅是为了介绍union的使用,实际上union的结果集大多不在一张表,而且也不会如此简单。
在使用union时,你应该注意,union必须连接两条或以上的select语句,并且每个查询必须包含相同的列,表达式或者聚集函数(顺序可以不同),此外,列的数据也必须兼容(不必完全相同,但需要能隐式转换)。
需要注意的是,union默认会合并重复行,比如上方的例子中在30岁以下的同时level大于3的教师就会被自动合并,如果不想被合并可以使用union all即可。
对union的排序不应该对单独的select语句进行排序,而是应该在最后进行一个order by排序即可。
# 5.4 全文索引(fulltext index)
手册参考:
- [官方手册8.0 - 全文索引功能](https://dev.mysql.com/doc/refman/8.0/en/fulltext-search.html)
- [官方手册8.0 - InnoDB全文索引](https://dev.mysql.com/doc/refman/8.0/en/innodb-fulltext-index.html)
2
3
全文索引通常用于加快基于大文本列的查询。MySQL早期的只有MyISAM引擎支持全文索引,不过在5.6之后,InnoDB引擎也开始支持全文索引,但是这个分词默认是针对英文的,中文的分词在5.7开始内置了ngram插件,这个插件可以支持中文、日语、韩语,所以对于想使用中文索引的人建议使用5.7+的版本。
InnoDB全文索引采用倒排索引设计。倒排索引存储一个单词列表,对于每个单词,还有一个该单词出现的文档列表。为了支持邻近搜索,每个单词的位置信息也被作为字节偏移进行存储。
对于大型数据集,将数据加载到没有FULLTEXT索引的表然后创建索引比将数据加载到具有现有FULLTEXT索引的表要快得多。
- 全文索引的创建与删除
创建:
CREATE TABLE opening_lines (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
opening_line TEXT(500),
author VARCHAR(200),
title VARCHAR(200),
FULLTEXT idx (opening_line)
) ENGINE=InnoDB;
2
3
4
5
6
7
CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);
-- 此方法添加的索引名即为列名
ALTER TABLE opening_lines
ADD FULLTEXT(opening_line)
2
3
将全文索引添加到没有FTS_DOC_ID列的表时,会返回InnoDB rebuilding table to add column FTS_DOC_ID警告。
如果您不关心CREATE FULLTEXT INDEX性能,请忽略该FTS_DOC_ID列, InnoDB为您创建它。
删除:
drop index idx on opening_lines
或者
alter table opening_lines drop index idx
- 使用全文索引
通过在where之后添加match(),against()即可根据全文索引搜索,需要注意的是,在默认分词插件下,通常是通过空格,逗号,句号进行分词,并且较短的字符串(默认是3)是不会被收录到单词列表。
select opening_line from opening_lines where match(opening_line) against('xxx')
默认情况下,搜索以不区分大小写的方式执行。要执行区分大小写的全文搜索,请对索引列使用区分大小写或二进制排序规则。例如,utf8mb4 可以为使用字符集的列分配排序规则 utf8mb4_0900_as_cs或 utf8mb4_bin使其区分大小写以进行全文搜索。
在某些情况下,使用like操作也能完成类似的操作,但是like的效率比较低(精度高)。而全文索引降低了一些精度,换来分析结果相关度,这一点是非常重要的,在下面我们将继续通过一个例子来介绍如何查询结果相关度或者权重。
select opening_line, match(opening_line) against('xxx') as weight from opening_lines
通过将match(opening_line) against('xxx')作为字段,我们可以看到每列对于该索引条件的权重。
默认通过全文索引查询的结果就是根据权重进行排序的,这一点是like这种高精度硬匹配所无法做到的。
在上述示例中,我们没有介绍全文索引的工作模式,默认情况下,全文索引使用自然语言模式,即IN NATURAL LANGUAGE MODE,除了该模式外,还有布尔模式和查询扩展模式。
更多参考:官方手册8.0 - 自然语言全文搜索 (opens new window)
布尔模式:布尔模式通常对字符串进行一些逻辑判断,比如判断某些单词存在同时某些单词不存在可以这样:
SELECT * FROM articles WHERE MATCH (title,body)
AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);
2
在上述示例中,+和-运算符分别指示一个词必须存在或不存在,IN BOOLEAN MODE用于确定采用布尔模式。
除了+和-之外还有许多其他的运算符,同时布尔查询也不会按照相关度进行排序。
更多参考:官方手册8.0 - 布尔全文搜索 (opens new window)
查询扩展模式:如果你想对结果进行扩展(即使结果不包含相关关键词),那么你可以使用with query expansion。
select opening_line from opening_lines where match(opening_line) against('xxx' with query expansion)
举个例子,你需要查询的词为Newtons,现在有一条记录为Apple fell on Newton's head.,那么与之相关词的就可能是head,所以结果可能就会返会包含head的记录。
更多参考:官方手册8.0 - 带有查询扩展的全文搜索 (opens new window)
- ngram 全文解析器
ngram是mysql 5.7开始内置的中文分词插件,根据n来确定分词基数的,在中文情况下,词语通常为两个字,所以ngram默认的token size就是2,但是这个值也可以进行配置,取值范围为[1,10].
- 命令行参数配置:
mysqld --ngram_token_size=2 - 配置文件:
[mysqld]
ngram_token_size=2
2
创建时指定ngram作为解析器:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
2
3
4
5
6
7
8
9
10
默认情况下,ngram 解析器使用默认停用词列表,其中包含英文停用词列表。对于适用于中文、日语或韩语的停用词列表,您必须创建自己的停用词列表。有关创建停用词列表的信息,请参阅全文停用词 (opens new window)。
Github中文停用词仓库: https://github.com/goto456/stopwords (opens new window)
对于自然语言模式,搜索词被转换为ngram词的联合。例如默认分词基数(2)的情况下,“长安城”将被分解成“长安 安城”,如果现在有两条记录,分别包含“长安”,“长安城”,那么在自然语言模式下,他们都将被匹配。
对于布尔模式,搜索词将转换为ngram短语搜索,同样在上述情况,则只有“长安城”被匹配。
如果你想查询分词的结果,官方有个示例:
mysql> USE test;
mysql> CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
mysql> SET NAMES utf8mb4;
INSERT INTO articles (title,body) VALUES
('数据库管理','在本教程中我将向你展示如何管理数据库'),
('数据库应用开发','学习开发数据库应用程序');
mysql> SET GLOBAL innodb_ft_aux_table="test/articles";
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE ORDER BY doc_id, position;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
更多参考:官方手册8.0 - ngram 全文解析器 (opens new window)
# 5.5 视图(view)
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的虚拟表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
- 数据库的设计和结构不会受到视图中的函数、where 或 join 语句的影响。
- 视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
- 视图名与表名不可重复。
- 使用复杂视图前请测试性能。
视图的好处
- 重用sql
- 简化sql
- 保护数据,只能操作表的特定部分
基本用法
# 创建视图
CREATE VIEW [Products Above Average Price] AS
SELECT ProductName,UnitPrice
FROM Products
WHERE UnitPrice>(SELECT AVG(UnitPrice) FROM Products);
# 查询视图
SELECT * FROM [Products Above Average Price];
# 查看视图创建过程
SHOW CREATE VIEW [Products Above Average Price];
# 更新视图
CREATE OR REPLACE VIEW [视图名] AS
SELECT column_name(s)
FROM table_name
WHERE condition;
# 删除视图
DROP VIEW [视图名];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 5.6 存储过程(Stored Procedure)
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集。
它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程的优点:可重用、使用简单、安全、高性能。
存储过程的创建权限与执行权限是分开的。
一般来说,存储过程的编写比基本SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验。
以下仅介绍基本的语法,实际上的存储过程十分复杂,建议参考:
- MySQL 存储过程 | 菜鸟教程 (opens new window)
- CREATE PROCEDURE and CREATE FUNCTION Statements | MySQL (opens new window)
基本用法
# 创建存储过程
CREATE PROCEDURE two_sum(
in num1 int, # 入参
in num2 int,
out sum int # 出参
)
begin
select num1+num2 into sum;
end;
# 查看存储过程创建过程
show create procedure two_sum;
# 调用存储过程
call two_sum(1,1,@ans);
# 查询存储过程返回的变量
select @ans; # 2
# 删除存储过程
drop procedure two_sum;
# 修改存储过程只能改变存储过程的特征,不能修改过程的参数以及过程体。
ALTER PROCEDURE proc_name [characteristic ...]
characteristic: {
COMMENT 'string'
| LANGUAGE SQL
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
默认的MySQL语句分隔符为;,如果你使用的是mysql命令行创建存储过程,则;会被忽略而导致语法错误。
解决办法是临时更改命令行实用程序的语句分隔符
# 临时修改为//
delimiter //
# 修改为正常情况
delimiter ;
2
3
4
# 5.7 游标(cursor)
游标是一个存储在MySQL服务器上的数据库查询, 它不是一条SELECT语句,而是被该语句检索出来的结果集。
游标在MySQL中只能与存储过程协同使用。
基础使用
create procedure testcursor(out res int)
begin
-- 定义本地变量done
declare done boolean default 0;
-- 创建游标
declare mycursor cursor
for
select id from gowow_admin;
-- '02000'事件(未找到条件,fetch循环到最后触发)触发设置done变量
declare continue handler for sqlstate '02000' set done = 1;
-- 打开游标
open mycursor;
-- 循环
repeat
-- 使用游标
fetch mycursor into res;
until done end repeat;
-- 关闭游标
close mycursor;
end;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
DECLARE语句的次序
DECLARE语句的发布存在特定的次序。用DECLARE语句定义的局部变量必须在定义任意游标或句柄之前定义,而句柄必须在游标之后定义。不遵守此顺序将产生错误消息。
# 5.8 触发器(trigger)
触发器是存储在数据库目录中的一组SQL语句。每当与表相关联的事件发生时,就会执行或触发SQL触发器,例如插入,更新或删除。
触发事刻有两种状态,分别是before和after。
使用before可以使用OLD来获取修改前的临时表数据。
使用after可以使用NEW来获取修改后的临时表数据。
基本用法
# 创建触发器 MySQL5之后不允许返回结果 所以使用变量接收
create trigger mytrigger after insert on [表名]
for each row select "my trigger is staring" into @res;
# 删除触发器
drop trigger mytrigger;
# 触发器不能被更新
2
3
4
5
6
7
更多参考:Trigger Syntax and Examples | MySQL (opens new window)
# 5.9 事务(transaction)
事务 的概念:一组sql语句,我们需要让它要么全部成功,要不直接失败。失败时触发的操作称之为回滚(rollback),当且仅当事务全部执行成功时,事务才被提交(commit)。同时事务中还可设置保留点(savepoint),它可以仅回滚到某个状态而不是回退整个事务。
基本使用
start transaction;
# 一些操作
...
savepoint sp1;
...
rollback to sp1;
...
rollback;
commit;
2
3
4
5
6
7
8
9
MySQL默认状态下autocommit = 1,所以你每次输入SQL语句都会自动提交并立即生效,你可以通过设置set autocommit = 0来关闭自动提交。
更多参考:START TRANSACTION, COMMIT, and ROLLBACK Statements | MySQL (opens new window)
# 6. 一些提示与建议
# 6.1 select语句的关键字顺序
依次为,select、from、where、group by、having、order by、limit
# 7. 常见SQL语句
# 7.1 数据库相关
# 创建数据库
create database [数据库名] character set [字符编码];
# 查看数据库
show databases;
# 查看数据库创建详情
show create database [数据库名字];
# 修改数据库编码
alter database [数据库名] character set [字符编码];
# 切换当前数据库
use [数据库名];
# 删除数据库
drop database [数据库名];
2
3
4
5
6
7
8
9
10
11
12
# 7.2 表相关
# 创建表格
create table [表名]
(
id int not null auto_increment,
name varchar(255) not null,
email varchar(255) null
enable tinyint default 1
primary key (id)
) engine = InnoDB;
# 新增列
alter table [表名] add age int(1);
# 删除列
alter table [表名] drop column age;
# 重命名表
rename table [旧表名] to [新表名];
# 删除表
drop table [表名];
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 7.3 用户权限相关
# 切换到mysql数据库
use mysql;
# 查看所有用户
select user from user;
# 新建用户
create user 'test' identified by 'password';
# 绑定主机
# create user 'test'@`localhost` identified by 'password';
# 重命名用户
rename user `test` to `test2`;
# 修改密码
alter user root identified by '123456';
# 修改当前用户密码
set password = '123456';
# 修改其他密码
set password for test2 = 'password';
#查看权限
show grants for `test2`; # 默认有个usage权限,其实就是无权限
# 赋予全数据表查询权限
grant select on learningmysql.* to test2;
# 撤销权限
revoke select on learningmysql.* from test2;
# 删除用户
drop user 'test2';
# 更多参考:https://dev.mysql.com/doc/refman/8.0/en/grant.html
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 7.4 字符集相关
# 查看字符集
show character set;
# 查看校对顺序
show collation;
2
3
4